This blog was started a month or two after I started experimentation, so I have some catching up to do. After coming up with my plan, a had a few things to do. Like learn how to do machine learning. The first thing I did was to take some existing code and train on some (any) data. Since I was going to be using a technique that worked with images, it made sense to work with some simple images at first. So I downloaded an example DCGANS and after a few weeks trying to understand what was going on, I managed to train it to pop out pictures of Jerry Garcia:

Now this worked, but I only had a few images of Jerry to work with (well, 32, but that’s not a lot in the world of machine learning). In fact, the machine was not so much learning to draw Jerry as to remember the images shown. But this was enough to show that essentially the technique was working and I had a decent base to start with.
Learn, and learn again
What did I get from this first foray? Quite a lot, but the main points were
- You need to really understand the data you provide
- The data needs a huge amount of processing
- There is potentially more code in getting the data format than required for the DCGANS!
- The process is SLOW. The image above took 9 hours to compute.
Go Grab Some Data
The next step was data collection. I took 5 shows of GD and roughly the same amount of other audio and split that up into 10 second sound slices. I then turned all that into Mel images. I had a problem here in that the code I had worked with 128×128 images, and it already took forever to train on that, so for the start I just resized all my Mels to 128×128. This would be awful for audio quality – probably even worse than some of those dreadful summer ’70 audience tapes – but you have to start somewhere.
I should note that doing the work in that simple paragraph was about 2/3 weeks on or off. Life does indeed get in the way. However, at the end of a pretty long learning session, I was able to post this image on to reddit for a few people to look at:
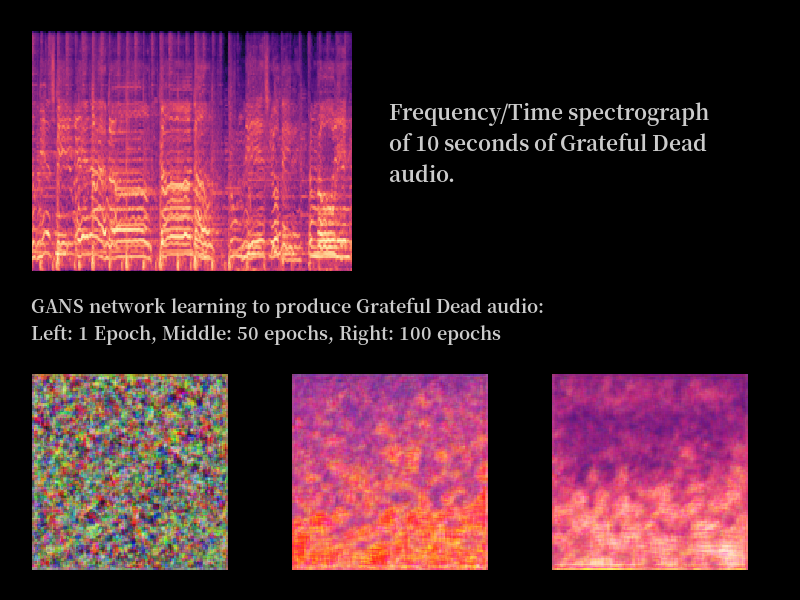
So there you go. I think you’re looking at the first computer generated Grateful Dead – although ideally you’d be listening to it. Problems? Well you’ll see the real image is both larger, has a different ratio and also, beyond some colour matching, is pretty much nothing like the final image on the right. Still, it’s a step in the right direction. It just needs a lot more training.
